In this part, we’re going to learn a bit about Git storage model of objects (commits, files etc). I’ll try not to dig too deep and will keep things relevant with day to day Git.
I actually wanted to write about merge and rebase in details but thought knowing basics of Git object model will make understanding merge and rebase easier.
This article is going to be more interactive, so keep your machine handy. I’m using macOS for it, these commands should work on Linux machines as well, though I’m not sure about Windows. If tree command is not installed already on mac, use brew install tree.
So let’s start now!
We’ll start with an empty Git repo - I’m pretty sure you know how to create an empty Git repo!
$ git init supermarine
$ cd supermarine
Now we have an empty Git repo without any file, or object in it except for .git directory. Let’s list down content of .git directory.
$ tree .git
.git
├── HEAD
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── post-update.sample
│ ├── ...
├── info
│ └── exclude
├── objects # Our point of attention!
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
We are going to focus entirely on .git/objects directory. objects directory is the one where Git stores actual data and metadata about files and directories. I’ll write another article on other files in .git directory which will cover them in detail. Also we’ll not discuss .git/objects/info and .git/objects/pack in this article, they are saved for another advance Git article.
Before going further, let’s have a quick look at Git storage model. Remember from last article, Working Tree is your local repo state and index is what holds the list of files added in Git. Also it was mentioned that index holds the files which are going to be committed next.
So what does a commit represent in Git?
Well, a commit objects is an snapshot of index. So every commit object is essentially a snapshot of all of the files in working tree at that state which were part of index.
Let’s have a quick look at terminologies:
- blob
Blobs are low level Git objects which hold data of individual committed files in compressed format. Every committed file has its own blob object. - tree
Tree is a data structure which holds information about other trees and blobs. Think of them as directory in file system. Directories can have more directories and files, and similarly Gittreecan have more trees and blobs. One major difference is that Gittreecan’t be empty! It’s because empty directories cannot be added in Git. (Though with some hacks empty trees can be created, we’ll not discuss them and will assume that it cannot be done!)
Each commit points to a tree which in turn holds information about other trees and blobs.
So whenever a file is added or modified, Git creates a new object for it. Usually few files are modified in each commit, so new commit objects reuse the old objects of un-modified files and add them to commit tree.
I’m borrowing following diagram from official Git doc to explain it further.
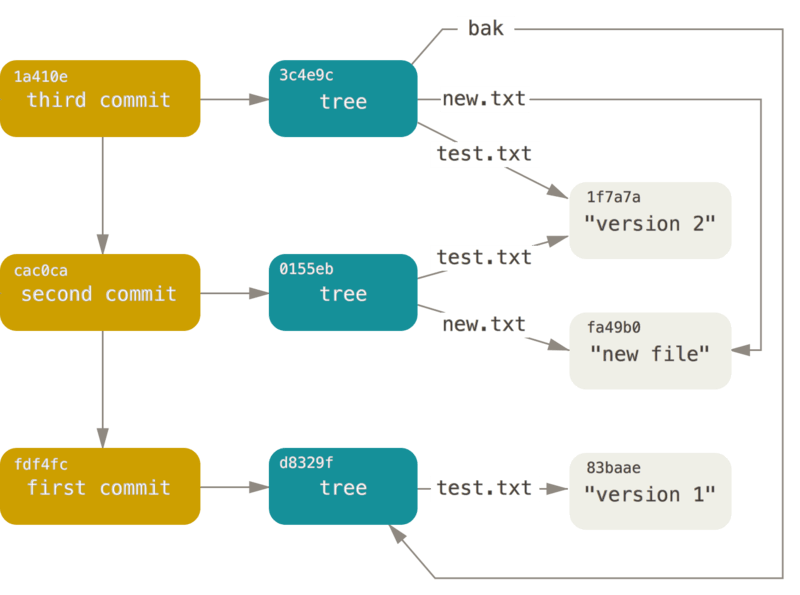 Explanation:
Explanation:
- First commit created a file
test.txtwith contentVersion 1. So first commit is pointing to a tree which is pointing to a blobtest.txt - Second commit created a new file
new.txtand updatedtest.txtwithVersion 2. So tree of second commit now contains 2 different objects, first fornew.txtand second for updatedtest.txt. - Third commit just moved original
test.txtto new directorybakand didn’t modify anything else. Now commit tree of third commit is reusing existing objects oftest.txtandnew.txtand it is also pointing to existing tree of first commit.
Let’s see these in action now!
$ $ printf "Spitfyre were awesome! \nThese were used in dunkirk." > spitfire.txt
$ git add spitfire.txt
$ git commit -m "Created spitfire"
[master (root-commit) ebd4507] Created spitfire
1 file changed, 2 insertions(+)
create mode 100644 spitfire.txt
Now as per our understanding of git storage so far, .git/objects directory should have 3 entries :- 1 for commit, 1 for tree and 1 for blob
$ tree .git/objects
.git/objects
├── 4a
│ └── 57147e48743464207d39cace45493836faef8d
├── 57
│ └── 7519a8cbd27e2e87b9fb68d3ca654d985cea97
├── eb
│ └── d4507807f6a597ac3fc68c4d12a075ba46b1a3
├── info
└── pack
From here one thing is clear that entry eb/d450... corresponds to commit (check commit hash in git commit command).
As mentioned previously, Git commit points to a tree
$ git cat-file -p HEAD
tree 4a57147e48743464207d39cace45493836faef8d
author Dheerendra Rathor <[email protected]> 1513524077 +0530
committer Dheerendra Rathor <[email protected]> 1513524077 +0530
Created spitfire
NOTE: git cat-file is a command to show content of git objects. -p flag is to print content. See more with git cat-file --help. Since Git stores object in compressed binary format, using less or cat or hexdump directly won’t help us much.
Now with output of cat-file we know that object 4a/5714... is a tree which commit HEAD is pointing to. Also we know that tree contains information about more trees and blobs. So the remaining object 57/7519... must be blob spitfire.txt.
$ git cat-file -p 4a5714
100644 blob 577519a8cbd27e2e87b9fb68d3ca654d985cea97 spitfire.txt
$ git cat-file -p 577519
Spitfyre were awesome!
These were used in dunkirk.
Our assumption was right, and as expected content of that blob is what we actually wrote. On a side note, content of Git tree object is:
- Each line represents a Git object
- Format of each line is
<permission> <type> <object hash> <name> - Entries are sorted by name of object
Now let’s create another file and see directory structure of .git/objects again.
$ echo "Spitfire Mk V" > spitfireV.txt
$ git add spitfireV.txt
$ git commit -m "Adding spitfire Mk V"
[master cb9c720] Adding spitfire Mk V
1 file changed, 1 insertion(+)
create mode 100644 spitfireV.txt
Can you now guess number of objects in .git/objects directory? Well, the answer must be 6. 1 new object each for commit, commit tree and new file.
$ tree .git/objects/
.git/objects/
├── 18
│ └── 0159944e98dc7cae80fd794d624d98b3b2f8ab
├── 4a
│ └── 57147e48743464207d39cace45493836faef8d
├── 57
│ └── 7519a8cbd27e2e87b9fb68d3ca654d985cea97
├── 8e
│ └── 130d3ca1e48d5b6a6761f50c6107f4cc2ebb98
├── cb
│ └── 9c720236bb25a03b0d3c2c302aed009c43b78c
├── eb
│ └── d4507807f6a597ac3fc68c4d12a075ba46b1a3
├── info
└── pack
3 new objects are 18/01599..., 8e/130d3..., cb/9c72.... From commit output, it is clear that object cb/9c720... is commit object. Let’s have a look at the content of it:
$ git cat-file -p HEAD
tree 180159944e98dc7cae80fd794d624d98b3b2f8ab
parent ebd4507807f6a597ac3fc68c4d12a075ba46b1a3
author Dheerendra Rathor <[email protected]> 1513524334 +0530
committer Dheerendra Rathor <[email protected]> 1513524334 +0530
Adding spitfire Mk V
So the output is just like we expected with additional line parent line in this commit. Remember Git is a DAG where each commit points to previous commit(s). Since last commit was the initial commit without any parent, that commit didn’t have parent line.
Now can you guess what is the content of tree 1801599? Remember each commit object is essentially a snapshot of all of the files at that state which were part of index. Let’s check it:
$ git cat-file -p 1801599
100644 blob 577519a8cbd27e2e87b9fb68d3ca654d985cea97 spitfire.txt
100644 blob 8e130d3ca1e48d5b6a6761f50c6107f4cc2ebb98 spitfireV.txt
Just like our directory structure, this tree contains information about both files in current directory. Also note that this tree is pointing to old object of spitfire.txt as there hasn’t been any change in that file.
I just noticed that I misspelled spitfire as spitfyre while creating spitfire.txt! I’m blaming spelling of fiendfyre for that :) Let’s correct it:
$ printf "Spitfire were awesome! \nThese were used in dunkirk." > spitfire.txt
$ git diff
diff --git a/spitfire.txt b/spitfire.txt
index 577519a..906d695 100644
--- a/spitfire.txt
+++ b/spitfire.txt
@@ -1,2 +1,2 @@
-Spitfyre were awesome!
+Spitfire were awesome!
These were used in dunkirk.
\ No newline at end of file
$ git commit -am "Fixed spitfire.txt"
[master f69bd03] Fixed spitfire.txt
1 file changed, 1 insertion(+), 1 deletion(-)
$ tree .git/objects/
.git/objects/
├── 18
│ └── 0159944e98dc7cae80fd794d624d98b3b2f8ab
├── 20
│ └── a2fe45675b3310e3531d3011b105ab42baa3f7
├── 4a
│ └── 57147e48743464207d39cace45493836faef8d
├── 57
│ └── 7519a8cbd27e2e87b9fb68d3ca654d985cea97
├── 8e
│ └── 130d3ca1e48d5b6a6761f50c6107f4cc2ebb98
├── 90
│ └── 6d6954b31f41512bd12601a968310f767358d5
├── cb
│ └── 9c720236bb25a03b0d3c2c302aed009c43b78c
├── eb
│ └── d4507807f6a597ac3fc68c4d12a075ba46b1a3
├── f6
│ └── 9bd035b682ea813465f56c5e0279764089df32
├── info
└── pack
$ git cat-file -p HEAD
tree 20a2fe45675b3310e3531d3011b105ab42baa3f7
parent cb9c720236bb25a03b0d3c2c302aed009c43b78c
author Dheerendra Rathor <[email protected]> 1513524598 +0530
committer Dheerendra Rathor <[email protected]> 1513524598 +0530
Fixed spitfire.txt
$ git cat-file -p 20a2fe
100644 blob 906d6954b31f41512bd12601a968310f767358d5 spitfire.txt
100644 blob 8e130d3ca1e48d5b6a6761f50c6107f4cc2ebb98 spitfireV.txt
After spellfix and new commit, we have 3 more git objects. f6/9bd03... is for HEAD, 20/a2f3... is for commit tree and 90/6d695... is for new spitfire.txt with fixed spelling. Let’s have a look at sizes of both old and new spitfire.txt blobs:
$ ls -l .git/objects/57/7519a8cbd27e2e87b9fb68d3ca654d985cea97
-r--r--r-- 1 dheerendra staff 60 Dec 17 20:50 .git/objects/57/7519a8cbd27e2e87b9fb68d3ca654d985cea97
$ ls -l .git/objects/90/6d6954b31f41512bd12601a968310f767358d5
-r--r--r-- 1 dheerendra staff 60 Dec 17 20:59 .git/objects/90/6d6954b31f41512bd12601a968310f767358d5
Well, both objects has same size even when new object has only 1 byte of change compared to old one.
$ git cat-file -p 906d69
Spitfire were awesome!
These were used in dunkirk.
Oh my god! Git is creating new object for entire file even when change is so small. Well, yes that is the reality of Git. Commits are nothing other than trees of files and directories which were part of index when commits were created. So if you create a file of say 100K size and modify just one character in it, Git will still create new object of 100K size!
This doesn’t mean that Git is totally stupid and un-optimized. Git is good at optimizations and that’s where pack comes into picture. Though we are not going to discuss pack in this post.
Let’s create a nested file structure and analyse Git objects one last time.
$ mkdir dunkirk
$ mkdir dunkirk/nolan
$ echo "Movie was awesome" > dunkirk/nolan/oscar.txt
$ git add dunkirk/nolan/oscar.txt
$ git commit -m "I loved Dunkirk"
[master cc36621] I loved Dunkirk
1 file changed, 1 insertion(+)
create mode 100644 dunkirk/nolan/oscar.txt
$ git cat-file -p HEAD^{tree}
040000 tree 28cf7c5e91550dbcfdb2f6cf968e0beb238561d0 dunkirk
100644 blob 906d6954b31f41512bd12601a968310f767358d5 spitfire.txt
100644 blob 8e130d3ca1e48d5b6a6761f50c6107f4cc2ebb98 spitfireV.txt
commit^{tree} is short reference to tree of that commit object aka commit-tree. commit-tree of HEAD now has 3 entries including entry for directory dunkirk.
$ git cat-file -p 28cf7c
040000 tree 5bac1384fdda4605cd6c03576be1c464c94b1098 nolan
$ git cat-file -p 5bac1
100644 blob 147fb0940ade8c084aeab211e070515d9572d640 oscar.txt
$ git cat-file -p 147fb
Movie was awesome
As we can see, tree object is like normal directory structure as mentioned earlier.
Takeaways
- In Git each commit stores information about entire file and directory structure. Each commit points to a Git data structure
treewhich is similar to directories. treeobject contains sorted information of all files and other trees.blobobject contains individual file data